Autocomplete at speed of light
Posted on February 7, 2019 • 2 minutes • 362 words
tldr: RediSearch - a full text search redis module that is super fast.
I learnt of RediSearch 2 years ago . It was a young project back then but seems very promising at time. When I revisit it last year, it’s quite mature already and was about to hit v1.0 so I did another test drive. The result was so good I put it on production few weeks later.
Its pros are:
- Fast (well!, it’s redis).
- No need to introduce another tech to our tech stack. You probably have Redis in your tech stack already anyway.
- API are very well documented. (I had a junior developer working on this feature for merely 1 week)
- If you’re using a redis client like ioredis
, you don’t need to add any additional dependency. ioredis already supports it
via
redis.call().
Fast 🚀
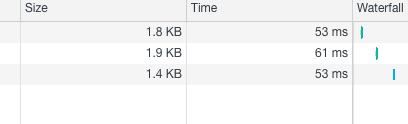
On my local machine, I can easily pull 1,500 requests per second (90k RPM). I guess it could be higher since I was running RediSearch in a Docker container. I was too lazy to set it up on my host machine.
Most of the query returns in sub-60ms. You can see for yourselves on MyTour.vn
Installing RediSearch
The official Docker images are available on Docker Hub as redislabs/redisearch. We’re using Docker and Kubernetes at work so it comes in very handy.
For example, the command below spawns a RediSearch docker container for you to try locally
docker run -d -p 7000:6379 redislabs/redisearch:latest redis-server --loadmodule /usr/lib/redis/modules/redisearch.so
Using RediSearch
Using RediSearch is quite simple. You just have to create indexes and preload your data to RediSearch.
You can also specify the data type(TEXT, NUMERIC) and its weight for each of the index field.
Once the data is loaded, you can call FT.SEARCH to do the autocomplete. We find BM25 algorithm works best for our use case instead of the default TFIDF.
In our use case, the whole thing is written in ~ 200 lines of code, cache population included.
Known issue
- RediSearch doesn’t work on case sensitive unicode characters; see issue #291 . However, there’s workaround for that. You can either normalize the query or you can keep the origin data in a separate field.